Improved datasets analyzed with Jupyter notebooks in virtual environments.
The bold blue links indicate the most recent or more elaborate documents. So, it is best to consult these documents first, before reading other.
For most topics that I handled I used Jupyter notebook, JupyterLab or VSCode. Sometimes I used QGIS 3.22-26, Notepad or MS Excel.
The Python 3.11 virtual environments were managed by conda & mamba.
Some notebooks have been published on the NBViewer platform, so these documents might take some time for the content to appear. However, most files were converted to html and are directly visible here.
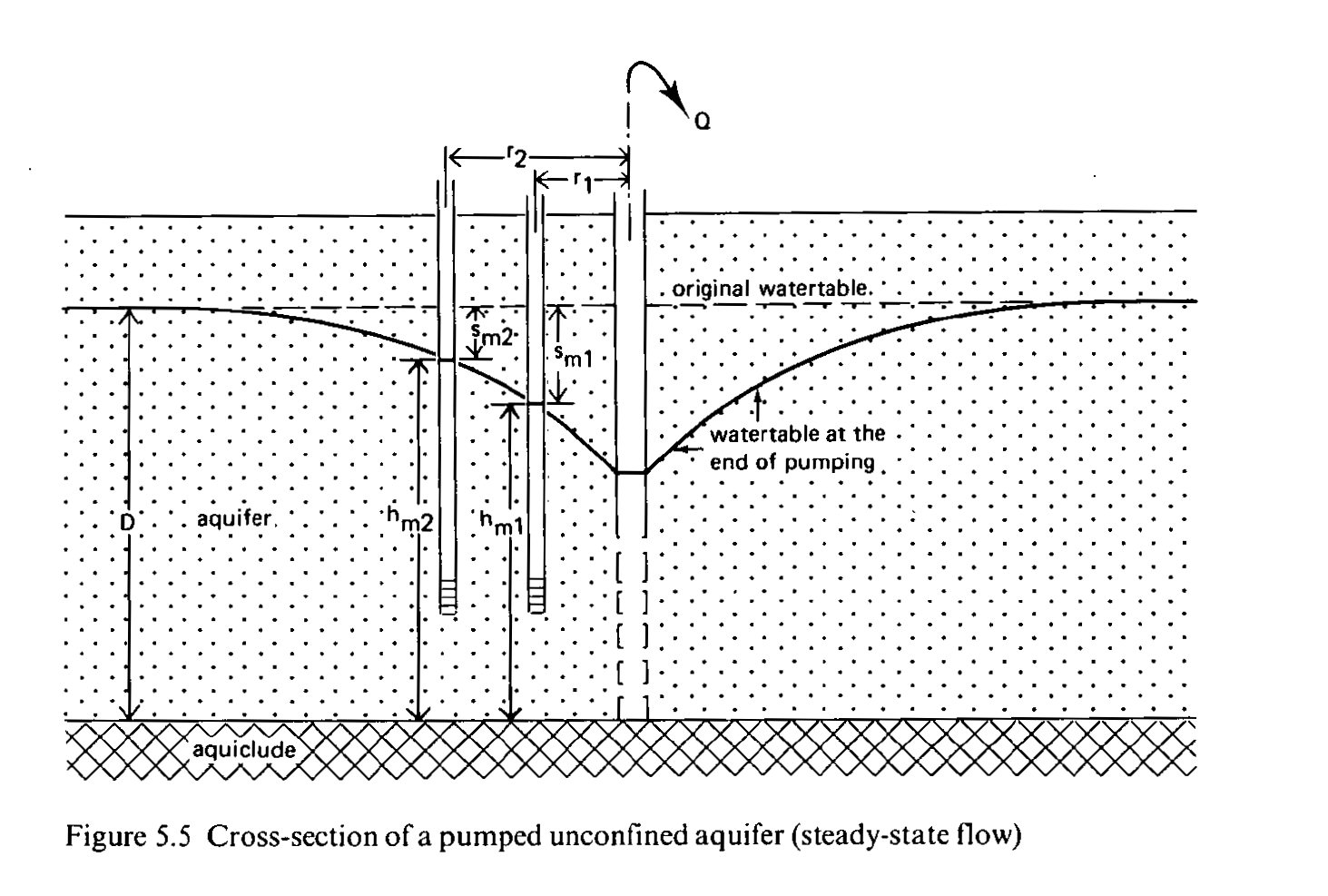
The Italian waterbodies dataset
The topic hydrology got my interest as practice domain, because this topic has very few clean or directly usable datasets.
You'll always have to clean up these datasets profoundly. Also you got to have some good domain knowledge for correct usage. The complexity of geohydrological systems is a reason why this kind of data is not taken as example datasets by the bulk of the data community.
A study of Italian waterbodies dataset
The datasets provided for the study of 4 Italian waterbodies were on purpose far from ideal: they contained numerous nan's, non-overlapping time series, intentional and human errors, scientifical inconsistencies, device malfunctioning. It added multiple layers of difficulty.
I tried to use the hydrology module Pastas, but soon I got stuck due to the lack of min. and max. temperature and evapotranspiration data. The same trouble with the lack of some info applies for the use of commercial models.
Also, waterbody characteristics change after a major event like a big flood, earth quake or a prolonged drought. The extreme dry seasons of 2012 and 2017 seem to have exhausted the storage reservoir of many springs.
Second attempt: collect better data and calculate indicators
After this, I started to experiment with one of the remaining waterbodies datasets: the data of water spring Lupa. This led me to assemble a completely new dataset by handpicking data from several sources. The new data had to be daily data, with almost no missing data starting from at least 2010.
This improved dataset was a better fit for time series analysis, and this led me to experiment with SARIMAX, VAR models, and the pmdArima, TensorFlow and Keras modules...
Here I've used a pretty simple Linear Regression Model using PyTorch built-ins. Also it is partly based on some more recent data, which I collected from raster/nc/satellite data files. Those weren't available more than 2-1.5 years ago.
I adjusted data for only a few missing data points.
The point here has been proven: good results in prediction can be obtained with decent data, which is trustworthy, and a system that is really understood.
So a combi of domain knowledge and stats/ml/dl know-how is the key.
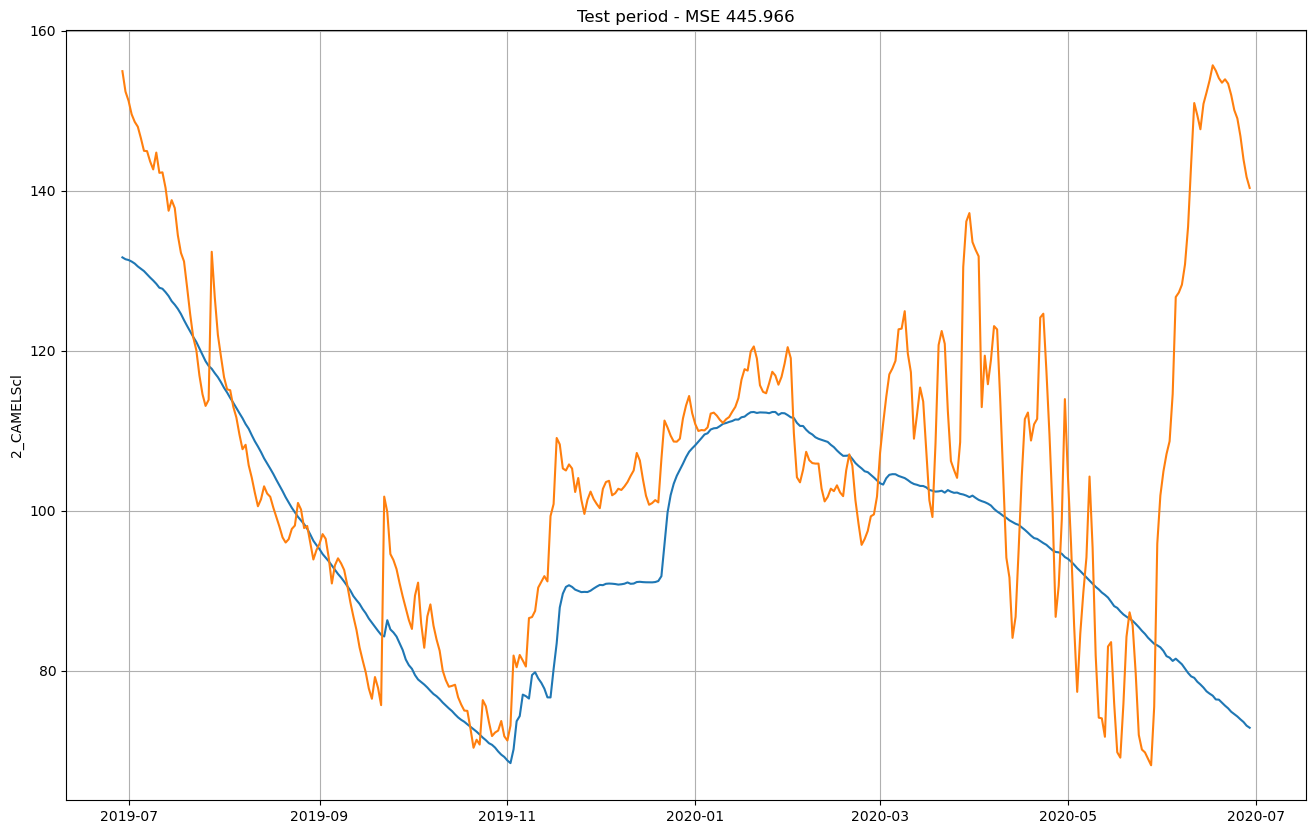
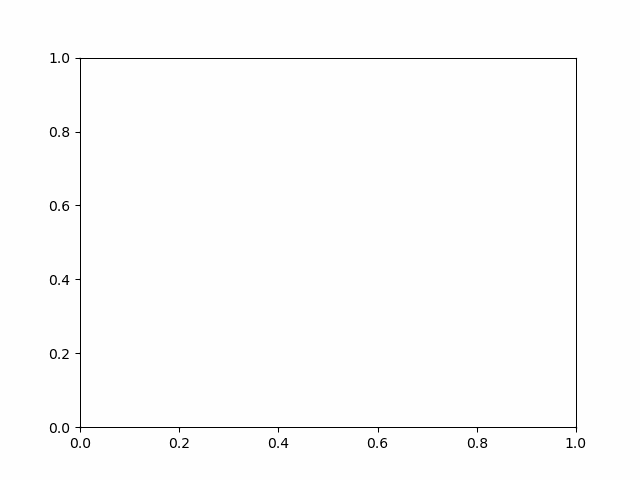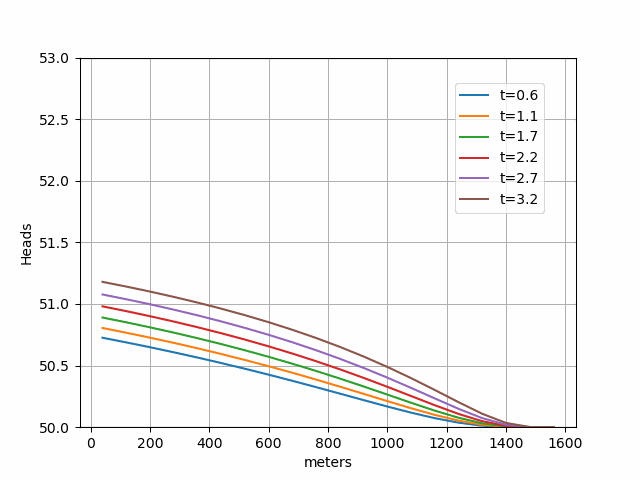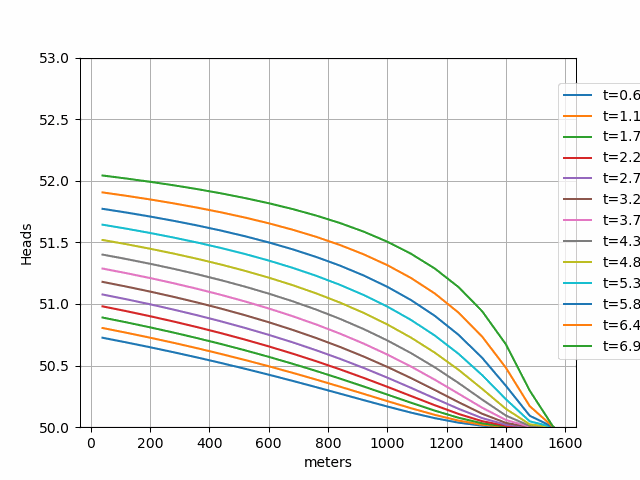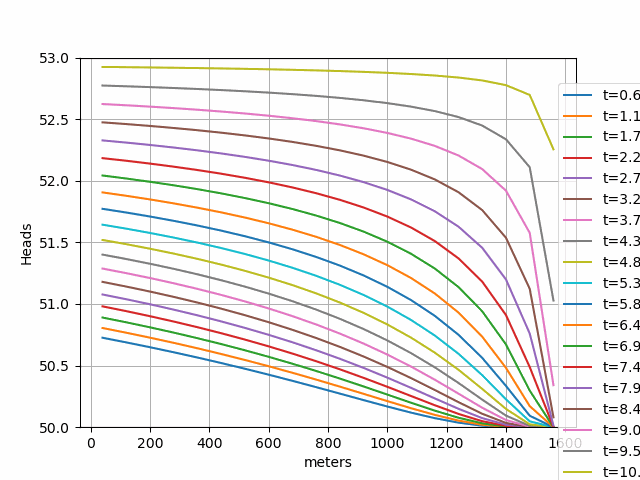
We'll preprocess the Chilean basins dataset files, train a model on a selection of basins which contain a fraction of carbonic/limestone rocks, and later compare the predictions to the observations over a span of 365 days.
Prediction vs real outflow: Lupa waterspring vs Chilean karstic & limestone Subset - July 2019-July 2020
Ahr river flood catastrophe of 14-15 July 2021 in Germany.
Some background info about the Ahr river and tributary debit data
My dataset is based on public data, and also on privately collected data. These are partly, or completely, no longer available (in hourly or 15 minutes frequency for public data) this time.
Background info about Ahr drainage basin
The flood mitigation regulations and the related disaster guidelines are a big pile of paper, and anno 2021, they were very confusing.
There are several layers of responsibility (starting with the Rhine) and also many exceptions, so everyone at their level of authority can point at someone else for an excuse.
This resulted in a real regulation paralysis in the days of the disaster. It just clearly didn't work.
In fact the whole story of failures and avoidable errors is Pulitzer price material.
On a practical note: the flood warning service for the Ahr valley had only been manned by 1volunteers, and they left at 17:00. German rules described that the Ahr basin did not warrant a 24 hours surveillance affair.
This is a shame, as for the Ahr with 900 km² drainage area, it misses the 1000 km² mark for enhanced surveillance. However, the soil mixture and soil depth properties tell a potential for disasters, which has been witnessed by historical records since 1346.
Finally, I want to inform that during my study on the Ahr, I found studies that mentioned that the Vesdre valley in Belgium has very similar rainfall-runoff characteristics. Of course, the rocks there are also mostly shale.
These are treecuttings that occured before the scheduled harvest time of the tree, because they were due to forcing actors like insects, storm, ...
A streamlit web app can be viewed at render.com, but bear in mind that this service must first start up and this could take more than 1 min. to showtime.
Another way is to watch the results is a not-so-recent video of this streamlit web app, which is viewable below.
Conda & Mamba: virtual environment and package management
Mamba is a reimplementation of the conda package manager in C++.
Parallel downloading of repository data and package files using multi-threading, libsolv for much faster dependency solving, and core parts of mamba are implemented in C++ for maximum efficiency.
At the same time, mamba utilizes the same command line parser, package installation and deinstallation code and transaction verification routines as conda to stay as compatible as possible.
Mamba is part of a bigger ecosystem to make scientific packaging more sustainable.
Such a promising introduction was an invitation to try out conda. For some time I was happy using it. However, after another time of running into (repairing) a broken conda environment, the joy left. So I searched for info about conda, and I found mamba. It turned out that with the aid of Mamba, I could repair most of my conda envs.
After that, I created new mamba environments for specific goals, based on custom yaml-files for env. and config options. (Some packages do not have yet support for python 3.11 e.g., some have no conda install...)
An example of a config yaml-file can be this file:
Conclusion: Mamba can be a powerful tool for managing and repairing virtual environments, but it takes some experience with config options and flags to unlock more potential.









")
